Speech Features¶
Audio data¶
Firstly, get audio data and sample rate from a wavfile. Using read_wav.py , we can get float data range from [-1, 1] .
from transform.feats.read_wav import ReadWav
config = {'sample_rate': 16000.0}
wav_path = 'sm1_cln.wav''
read_wav = ReadWav.params(config).instantiate()
audio_data, sample_rate = read_wav(wav_path)
The raw signal has the following form in the time domain:
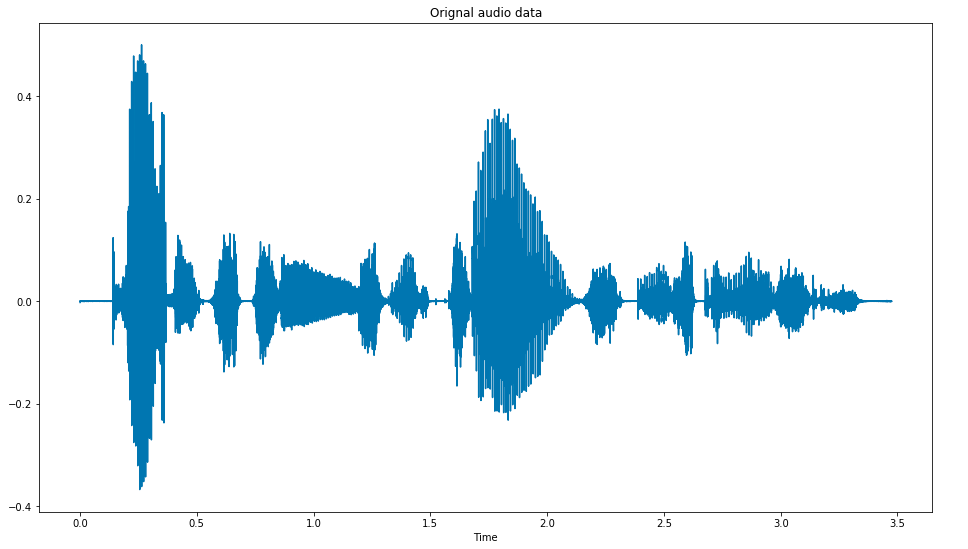 audio data of wavfile
audio data of wavfile
Spectrum¶
The change of speech in the time domain is fast and complicated, and we often need to use Fourier Transform to convert it to the time-frequency domain. The transform of the digital audio signal is called Short Time Fourier Transform (STFT), which consists of pre-emphasis (optional), framing, window and Fast Fourier Transform.
Pre-Emphasis¶
Because of glottal excitation and oral and nasal radiation, the high frequency of power spectrum drops at 6 dB/octave above 800Hz. Pre-emphasis can increase the high-frequency content, which can make spectrum more flatten and maintain the same signal-to-noise ratio in the entire frequency band. Generally, pre-emphasis is achieved by a first-order FIR high-pass filter,
y(n)=x(n)-ax(n-1), 0.9 < a < 1.0
where a is the pre-emphasis coefficient.
The comparison of the spectrum after pre-emphasis (down, a=0.97).
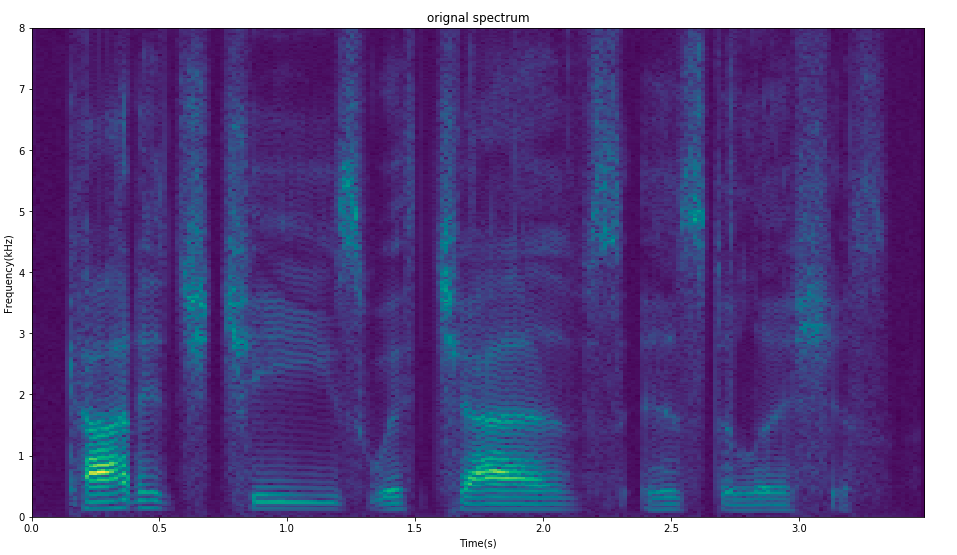 Spectrum of orignal data
Spectrum of orignal data
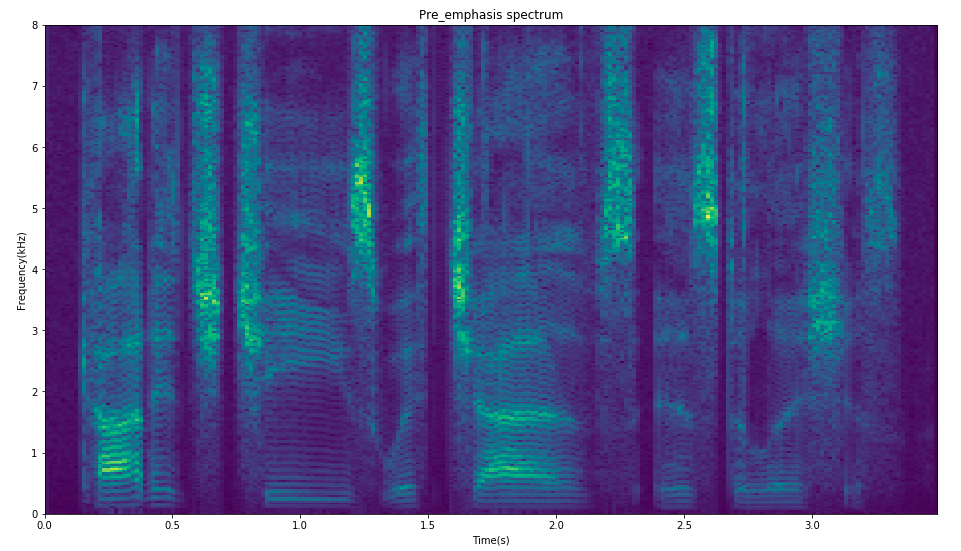 Spectrum of pre_emphasis data
Spectrum of pre_emphasis data
Framing¶
Fourier transform requires the signal to be stable, but the entire signal in the real change over time. So, we need to split the signal into short-time frames, which can be regarded as stable. The length of frames need to meet the following requirements: firstly, it is short enough to ensure that the signal in the frame is stable, so the length of a frame should be less than the length of phoneme (50-200ms), secondly, it must contain enough vibration periods, and the fundamental frequency of male is 100Hz (T=10ms) and female is 200Hz (T=5ms), that is the length should not smaller than 20 ms. In summary, the frame length is generally range 20ms to 50ms. The default length of a frame is 25ms with 15ms overlap between consecutive frames of Kaldi.
Window¶
After framing, we need to apply a window function such as the Hamming window to each frame to reduce the spectrum leakage error. A Hamming window has the following form:
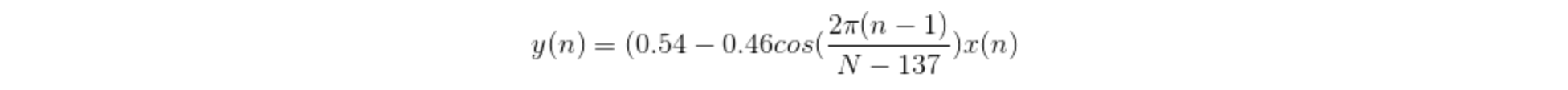 Hamming
where, n ranges from 0 to N, N is the window length.
Each frame of the signal is multiplied by a smooth window function to make both ends of a frame smoothly attenuated to
zeros, which can reduce the intensity of the side lobe after Fourier transform and obtain a higher quality spectrum. In order to
avoid loss of information, we need to make up for it using overlap.
Hamming
where, n ranges from 0 to N, N is the window length.
Each frame of the signal is multiplied by a smooth window function to make both ends of a frame smoothly attenuated to
zeros, which can reduce the intensity of the side lobe after Fourier transform and obtain a higher quality spectrum. In order to
avoid loss of information, we need to make up for it using overlap.
Fast Fourier Transform¶
We need to perform Discrete Fourier Transform (DFT) for digital audios. DFT is defined as,
 DFT
Due to the high computational complexity of DFT, we usually use Fast Fourier Transform (FFT) instead. The number of FFT point (Nfft) is generally an integer power of 2, and must be notsmaller than the frame length. When the frame length is not equal to Nfft, zero padding can be used.
Now, we can do an N-point FFT on each frame to calculate the frequency spectrum, which is also called
Short-Time-Fourier-Tranform (STFT), where N is typically 256 or 512.
Using
DFT
Due to the high computational complexity of DFT, we usually use Fast Fourier Transform (FFT) instead. The number of FFT point (Nfft) is generally an integer power of 2, and must be notsmaller than the frame length. When the frame length is not equal to Nfft, zero padding can be used.
Now, we can do an N-point FFT on each frame to calculate the frequency spectrum, which is also called
Short-Time-Fourier-Tranform (STFT), where N is typically 256 or 512.
Using spectrum.py , we can get a complex matrix with dimensions (num_frequency, num_frame), which means that the signal is composed of num_frequency sine waves with different
phases and magnitudes. For each T-F bin, the absolute value of the FFT is the magnitude, and the phase is the initial phase of the sine wave. The corresponding spectrum is called
the amplitude spectrum and the phase spectrum, as shown in the figure below.
from transform.feats.spectrum import Spectrum
config = {'window_length': 0.025,
'frame_length': 0.010,
'preEph_coeff': 0.97,
'window_type': 'hamming'}
wav_path = 'sm1_cln.wav''
read_wav = ReadWav.params().instantiate()
audio_data, sample_rate = read_wav(wav_path)
spectrum = Spectrum.params(config).instantiate()
spectrum_data = spectrum(input_data, sample_rate)
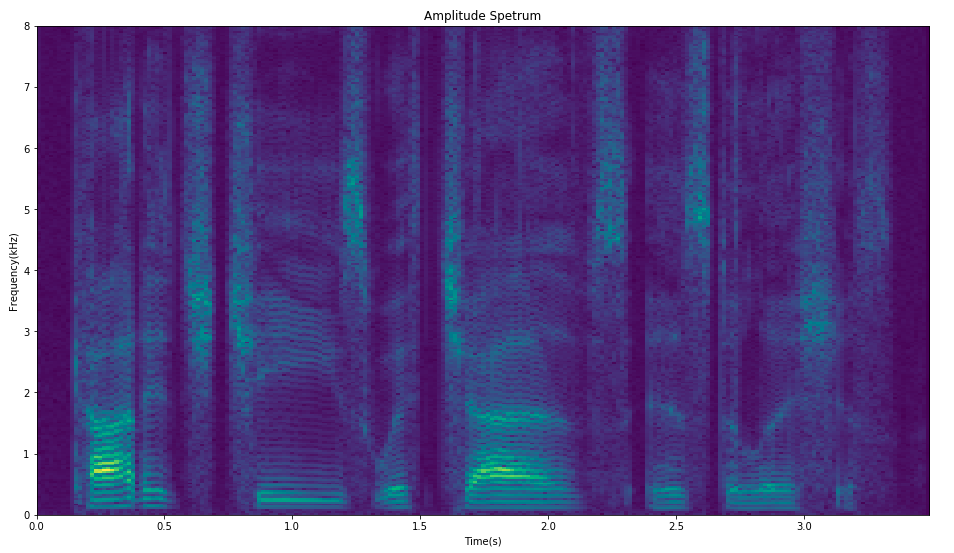 Amplitude Spectrum
Amplitude Spectrum
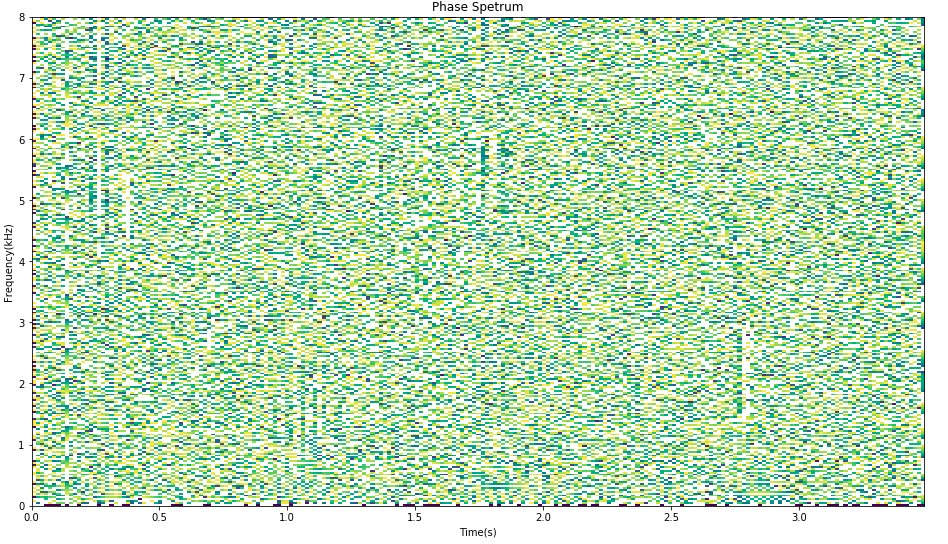 Phase Spectrum
Phase Spectrum